
แชร์ 9 ข้อดีของการมีบ้านที่หลายคนไม่เคยรู้มาก่อน
การมีบ้านไม่เพียงแต่เป็นการสร้างที่อยู่อาศัย แต่ยังเป็นการสร้างพื้นที่สำหรับการเติบโต ความสุข และความทรงจำของครอบครัว ด้านล่างนี้คือข้อดีหลักๆ ของการมีบ้าน
วัตถุประสงค์ของคอร์สอบรมผู้บริหาร
คอร์สอบรมผู้บริหารหรือหลักสูตรอบรมผู้บริหารเป็นหลักสูตรที่ออกแบบมาเพื่อพัฒนาทักษะและความสามารถของผู้บริหารในระดับต่างๆ ไม่ว่าจะเป็นผู้จัดการ ผู้อำนวยการ หรือผู้บริหารระดับสูง

ฮวงจุ้ยคอนโด แบบไหนอยู่แล้วสุข การงานมั่นคง การเงินมั่งคั่ง
ฮวงจุ้ยคอนโด ทำเลที่ตั้ง การเลือกชั้น เลขห้อง และสีมงคล ตามธาตุทั้ง 5 ได้แก่ ธาตุดิน ธาตุทอง ธาตุน้ำ ธาตุไม้ ธาตุไฟ ลักษณะห้องที่ต้องเลี่ยง พร้อมวิธีปรับฮวงจุ้ย

เคล็ดลับต้องรู้สู่ความสำเร็จ กับเทรนด์ธุรกิจในปี 2024
เทรนด์ธุรกิจมาแรงภายในปี 2024 มีการเปลี่ยนแปลงและการพัฒนาที่น่าสนใจหลายด้าน ซึ่งสะท้อนถึงการปรับตัวและการนำนวัตกรรมเข้ามาใช้เพื่อเติบโตและแข่งขันในตลาดขณะนี้

ปั้นหุ่นเฟิร์มสำหรับผู้ชาย แค่ทำ 5 ท่าออกกำลังกายนี้!
หนุ่ม ๆ มาปั้นหุ่นให้เฟิร์ม เพิ่มกล้ามเนื้อ เสริมสร้างความแข็งแรงและความทนทานของร่างกาย ด้วยท่าออกกำลังกาย Push-up, Squat, Deadlift, Pull-up และ Plank เริ่มเลย!

ห้ามพลาด! 10 คุณสมบัติ Microsoft Excel พร้อมคีย์ลัดสุดว้าว!
Ms Excel ซอฟต์แวร์ที่มีความสามารถหลากหลายและได้รับความนิยม ใช้สำหรับจัดการข้อมูล วิเคราะห์ รวมถึงสร้างรายงานอย่างมืออาชีพ มาดูคีย์ลัดที่ช่วยให้งานของคุณเร็วขึ้น

5 สถานที่ท่องเที่ยวยอดฮิตในภูเก็ตที่ไม่ควรพลาด
สถานที่ท่องเที่ยวของภูเก็ต นอกจากทะเลที่สวยงาม ยังมีอาคารบ้านเรือนและสถาปัตยกรรมเก่าแก่ ที่สะท้อนถึงวิถีชีวิตและวัฒนธรรมท้องถิ่น รวมถึงเสน่ห์ของธรรมชาติที่ไม่ควรพลาด
5 สถานที่ท่องเที่ยวยอดฮิตในภูเก็ตที่ไม่ควรพลาด
สถานที่ท่องเที่ยวของภูเก็ต นอกจากทะเลที่สวยงาม ยังมีอาคารบ้านเรือนและสถาปัตยกรรมเก่าแก่ ที่สะท้อนถึงวิถีชีวิตและวัฒนธรรมท้องถิ่น รวมถึงเสน่ห์ของธรรมชาติที่ไม่ควรพลาด

4 เคล็ดลับหน้าใสแบบไอดอล บำรุงให้สวยฉ่ำจากภายในสู่ภายนอก!
ผิวสวยใสใคร ๆ ก็มีได้! อย่าลืมดูแลให้ครบ ด้วย 4 ขั้นตอน ตั้งแต่ การทำความสะอาด การบำรุงผิว ทาครีมกันแดดเป็นประจำ และที่สำคัญ ปรับเปลี่ยนไลฟ์สไตล์เพื่อสุขภาพที่ดี

ดริปวิตามินผิว (Vitamin drip) คืออะไร อันตรายหรือไม่?
การดริปวิตามินผิว (Vitamin drip) เป็นการฉีดวิตามินเข้าเส้นเลือดโดยตรง เพื่อเพิ่มประสิทธิภาพในการดูดซึม ลดอาการเหนื่อยล้า ปรับสภาพผิว และเสริมสร้างระบบภูมิคุ้มกัน
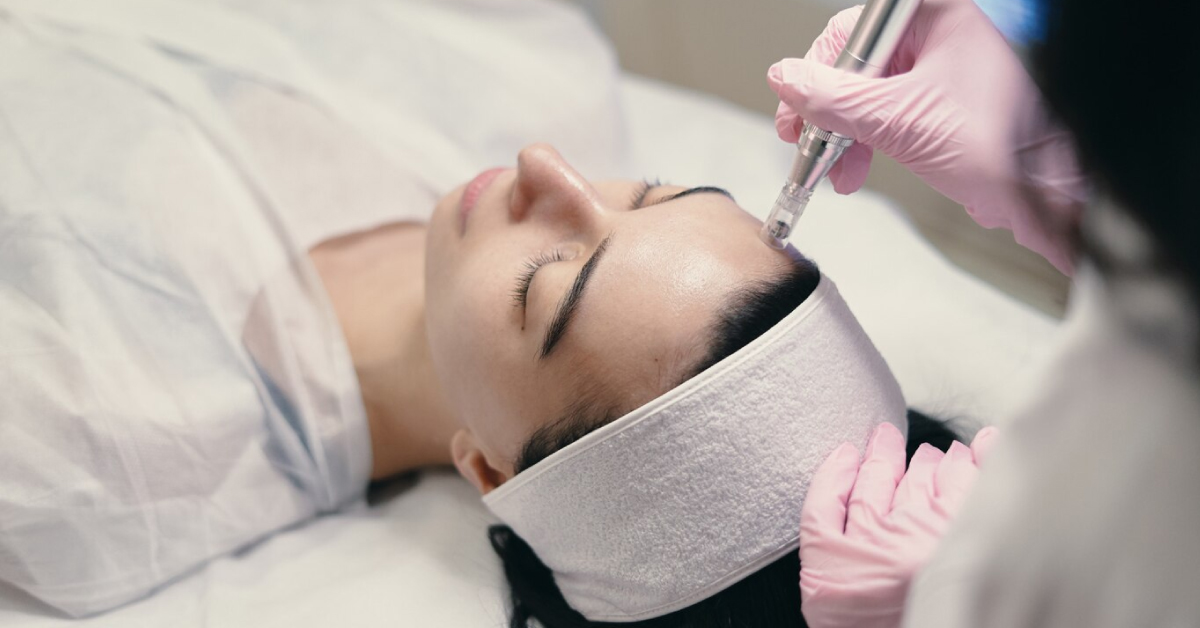
ทำความรู้จักกับ “หัตถการความงาม” มีกี่ประเภท อะไรบ้าง?
หัตถการความงาม มีหลายประเภท เช่น การฉีดฟิลเลอร์ โบท็อกซ์ เสริมหน้าอก ทำจมูก ลดไขมัน ฯลฯ ควรปรึกษาแพทย์เฉพาะทาง เพื่อให้เข้าใจความเสี่ยงและความคาดหวังที่จะได้รับ

สวยเสกได้! รู้จัก “โบท็อกซ์” เคล็ดลับหน้าเป๊ะปังแบบดาราท่านหนึ่ง
โบท็อกซ์ ชื่อทางการค้าของสารที่ได้จาก Botulinum Toxin Type A ทางเลือกในการคงความอ่อนเยาว์ ลดกราม กระชับใบหน้า ที่สำคัญจะต้องเลือกฉีดโดยแพทย์ที่มีความรู้เฉพาะทาง
ปั้นหุ่นเฟิร์มสำหรับผู้ชาย แค่ทำ 5 ท่าออกกำลังกายนี้!
หนุ่ม ๆ มาปั้นหุ่นให้เฟิร์ม เพิ่มกล้ามเนื้อ เสริมสร้างความแข็งแรงและความทนทานของร่างกาย ด้วยท่าออกกำลังกาย Push-up, Squat, Deadlift, Pull-up และ Plank เริ่มเลย!
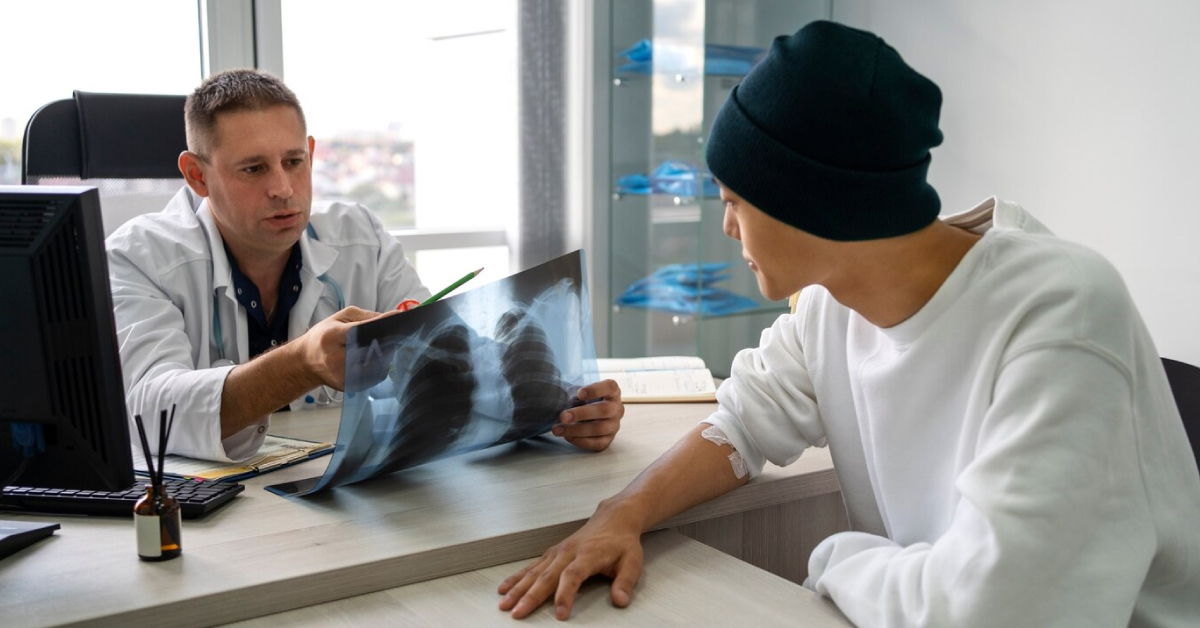
มะเร็งปอด โรคยอดฮิตในผู้ชาย ป้องกันได้ ด้วยการตรวจคัดกรอง
มะเร็งปอด หนึ่งในโรคมะเร็งที่เป็นสาเหตุการตายสูงสุดทั่วโลก พบได้ในทุกเพศ แต่สำหรับผู้ชาย มีบางปัจจัยที่ทำให้เกิดความเสี่ยงสูงกว่า มาทำความรู้จักโรคนี้ให้มากขึ้น

อาหารเสริมแคลเซียม ผู้สูงอายุตัวช่วยที่ทำให้กระดูกแข็งแรง
สุขภาพเป็นเรื่องที่สำคัญและไม่ควรมองข้ามโดยเฉพาะในวัยผู้สูงอายุ ยิ่งอายุมากขึ้นมวลกระดูกก็เริ่มลดลง การทานอาหารเสริมแคลเซียม ผู้สูงอายุจึงมีความสำคัญและจำเป็นอย่างมาก

วิธีการดูแลรักษาข้อเข่าเสื่อมที่ถูกต้องในผู้ป่วย
โรคข้อเข่าเสื่อมหรือโอสเตียร์อาร์ไธรติส (Osteoarthritis – OA) ของข้อเข่า เป็นโรคที่พบบ่อยที่สุดในกลุ่มของโรคข้ออักเสบเสื่อม ซึ่งเกิดจากการสึกหรอและการเสื่อมของกระดูกอ่อน (cartilage)

เคยสงสัยไหม? เหตุใด Netflix ถึงกลายเป็นสตรีมมิ่งอันดับหนึ่ง มาดูกัน!
ทำความรู้จักกับที่มาของ Netflix จากบริษัทเช่า dvd ผ่านไปรษณีย์สู่บริการสตรีมมิ่งอันดับหนึ่ง ผู้ผลิตซีรีส์/ภาพยนตร์สำหรับผู้ชมทุกประเทศ

วิธีเลือกรองเท้าวิ่งสำหรับมือใหม่ วิ่งสบาย ไม่เจ็บเท้า
หากคุณเป็นคนรักการวิ่งและต้องการเริ่มต้นในโลกของการวิ่งการเลือกรองเท้าวิ่งที่เหมาะสมเป็นสิ่งสำคัญมาก รองเท้าที่ถูกต้องจะทำให้คุณวิ่งได้สบาย

Cruise Control ฟังก์ชั่นทุ่นแรงที่หลายคนอาจมองข้าม!
ระบบควบคุมความเร็วอัตโนมัติ (Cruise Control) ระบบที่ช่วยให้รถยนต์สามารถคงความเร็วที่ตั้งไว้โดยไม่ต้องเหยียบคันเร่ง ซึ่งถูกออกแบบเพื่อเพิ่มความสะดวกสบายในการขับขี่

เสน่ห์เหนือกาลเวลาของ แฟชั่นวินเทจ (Vintage)
วินเทจ หมายถึง สิ่งของหรือสไตล์ที่มาจากยุคก่อน โดยเฉพาะในช่วงปี 1920 ถึง 1980 เป็นสิ่งของที่มีอายุระหว่าง 20-100 ปี ทุกชิ้นเป็นการเล่าเรื่องราวจากยุคที่ผ่านมา

รู้จัก Y2K เทรนด์แฟชั่นยุค 2000 ที่กลับมาฮิตอีกครั้ง
Y2K is BACK ! เมื่ออดีตที่สดใส กลับมาไฉไล ในปัจจุบัน ช่วงนี้แฟชั่นที่ฮิตติดเทรนด์ที่สุดคงไม่พ้นคำว่า Y2K

5 ความเชื่อของคนไทย ที่รู้ไว้ไม่เสียหาย
ความเชื่อกับคนไทยอยู่คู่กันมาช้านาน โดยเรามักจะได้ยินจากญาติผู้ใหญ่ ในบางครั้งความเชื่อเหล่านี้ยังแฝงไว้ซึ่งกลอุบาย เพื่อเตือนให้ระมัดระวังอันตรายที่อาจเกิดขึ้น

ทายนิสัยจากทั้ง 7 วันเกิด แม่นจนขนลุก!
ความเชื่อเกี่ยวกับดวงชะตา และการทำนาย อยู่คู่กับคนไทยมาอย่างช้านาน ล้วงให้ลึกถึงตัวตน ของผู้ที่เกิดวันต่าง ๆ จะมีลักษณะนิสัยแบบไหนบ้าง? มาดูไปพร้อมกันในบทความนี้
วัตถุประสงค์ของคอร์สอบรมผู้บริหาร
คอร์สอบรมผู้บริหารหรือหลักสูตรอบรมผู้บริหารเป็นหลักสูตรที่ออกแบบมาเพื่อพัฒนาทักษะและความสามารถของผู้บริหารในระดับต่างๆ ไม่ว่าจะเป็นผู้จัดการ ผู้อำนวยการ หรือผู้บริหารระดับสูง
เสน่ห์เหนือกาลเวลาของ แฟชั่นวินเทจ (Vintage)
วินเทจ หมายถึง สิ่งของหรือสไตล์ที่มาจากยุคก่อน โดยเฉพาะในช่วงปี 1920 ถึง 1980 เป็นสิ่งของที่มีอายุระหว่าง 20-100 ปี ทุกชิ้นเป็นการเล่าเรื่องราวจากยุคที่ผ่านมา
5 ความเชื่อของคนไทย ที่รู้ไว้ไม่เสียหาย
ความเชื่อกับคนไทยอยู่คู่กันมาช้านาน โดยเรามักจะได้ยินจากญาติผู้ใหญ่ ในบางครั้งความเชื่อเหล่านี้ยังแฝงไว้ซึ่งกลอุบาย เพื่อเตือนให้ระมัดระวังอันตรายที่อาจเกิดขึ้น
ทายนิสัยจากทั้ง 7 วันเกิด แม่นจนขนลุก!
ความเชื่อเกี่ยวกับดวงชะตา และการทำนาย อยู่คู่กับคนไทยมาอย่างช้านาน ล้วงให้ลึกถึงตัวตน ของผู้ที่เกิดวันต่าง ๆ จะมีลักษณะนิสัยแบบไหนบ้าง? มาดูไปพร้อมกันในบทความนี้
ฮวงจุ้ยคอนโด แบบไหนอยู่แล้วสุข การงานมั่นคง การเงินมั่งคั่ง
ฮวงจุ้ยคอนโด ทำเลที่ตั้ง การเลือกชั้น เลขห้อง และสีมงคล ตามธาตุทั้ง 5 ได้แก่ ธาตุดิน ธาตุทอง ธาตุน้ำ ธาตุไม้ ธาตุไฟ ลักษณะห้องที่ต้องเลี่ยง พร้อมวิธีปรับฮวงจุ้ย

แก้ทางสามแพร่งด้วย 4 หลักฮวงจุ้ย สร้างความสุขสมดุลในบ้าน
ทางสามแพร่งแก้ได้ด้วยหลักฮวงจุ้ย โดยการวางตำแหน่งประตู การใช้สิ่งของตกแต่ง ต้นไม้ ฉากกั้น รวมถึงการใช้สี ทั้งหมดนี้ สามารถเสริมสมดุลและพลังงานที่ดีให้กับบ้านได้
วัตถุประสงค์ของคอร์สอบรมผู้บริหาร
คอร์สอบรมผู้บริหารหรือหลักสูตรอบรมผู้บริหารเป็นหลักสูตรที่ออกแบบมาเพื่อพัฒนาทักษะและความสามารถของผู้บริหารในระดับต่างๆ ไม่ว่าจะเป็นผู้จัดการ ผู้อำนวยการ หรือผู้บริหารระดับสูง
เสน่ห์เหนือกาลเวลาของ แฟชั่นวินเทจ (Vintage)
วินเทจ หมายถึง สิ่งของหรือสไตล์ที่มาจากยุคก่อน โดยเฉพาะในช่วงปี 1920 ถึง 1980 เป็นสิ่งของที่มีอายุระหว่าง 20-100 ปี ทุกชิ้นเป็นการเล่าเรื่องราวจากยุคที่ผ่านมา

โรคซึมเศร้า (Depression) สาเหตุ อาการ และการรักษา
โรคซึมเศร้าเป็นภาวะทางจิตเวชที่ทำให้บุคคลมีความรู้สึกเศร้าสลด สูญเสียความสนใจหรือความสุขในกิจกรรมที่เคยชอบ ซึ่งส่งผลกระทบต่อคุณภาพชีวิตของผู้ป่วยได้อย่างลึกซึ้ง

โรคย้ำคิดย้ำทำ (OCD) คืออะไร? สาเหตุ อาการ และวิธีรักษา
โรคย้ำคิดย้ำทำ (Obsessive-Compulsive Disorder) สภาวะที่ผู้ป่วยมีความจำเป็นต้องคิด (Obsessions) และ/หรือทำ (Compulsions) ซ้ำ ๆ เพื่อลดความรู้สึกเครียดหรือความวิตกกังวล
รู้จัก Y2K เทรนด์แฟชั่นยุค 2000 ที่กลับมาฮิตอีกครั้ง
Y2K is BACK ! เมื่ออดีตที่สดใส กลับมาไฉไล ในปัจจุบัน ช่วงนี้แฟชั่นที่ฮิตติดเทรนด์ที่สุดคงไม่พ้นคำว่า Y2K
เสน่ห์เหนือกาลเวลาของ แฟชั่นวินเทจ (Vintage)
วินเทจ หมายถึง สิ่งของหรือสไตล์ที่มาจากยุคก่อน โดยเฉพาะในช่วงปี 1920 ถึง 1980 เป็นสิ่งของที่มีอายุระหว่าง 20-100 ปี ทุกชิ้นเป็นการเล่าเรื่องราวจากยุคที่ผ่านมา
เสน่ห์เหนือกาลเวลาของ แฟชั่นวินเทจ (Vintage)
วินเทจ หมายถึง สิ่งของหรือสไตล์ที่มาจากยุคก่อน โดยเฉพาะในช่วงปี 1920 ถึง 1980 เป็นสิ่งของที่มีอายุระหว่าง 20-100 ปี ทุกชิ้นเป็นการเล่าเรื่องราวจากยุคที่ผ่านมา
รู้จัก Y2K เทรนด์แฟชั่นยุค 2000 ที่กลับมาฮิตอีกครั้ง
Y2K is BACK ! เมื่ออดีตที่สดใส กลับมาไฉไล ในปัจจุบัน ช่วงนี้แฟชั่นที่ฮิตติดเทรนด์ที่สุดคงไม่พ้นคำว่า Y2K
วัตถุประสงค์ของคอร์สอบรมผู้บริหาร
คอร์สอบรมผู้บริหารหรือหลักสูตรอบรมผู้บริหารเป็นหลักสูตรที่ออกแบบมาเพื่อพัฒนาทักษะและความสามารถของผู้บริหารในระดับต่างๆ ไม่ว่าจะเป็นผู้จัดการ ผู้อำนวยการ หรือผู้บริหารระดับสูง

ไขข้อสงสัยอาการมือเท้าชา ขาดวิตามินอะไร
มือเท้าชา ขาดวิตามินอะไรหรืออาการมือชา เท้าชาเป็นอาการที่ค่อนข้างพบบ่อย ซึ่งเกิดจากความผิดปกติหรือความบกพร่องในการทำงานของเส้นประสาท มักเป็นการสูญเสียหรือลดลงของความรู้สึกที่มือหรือเท้า
วิธีการดูแลรักษาข้อเข่าเสื่อมที่ถูกต้องในผู้ป่วย
โรคข้อเข่าเสื่อมหรือโอสเตียร์อาร์ไธรติส (Osteoarthritis – OA) ของข้อเข่า เป็นโรคที่พบบ่อยที่สุดในกลุ่มของโรคข้ออักเสบเสื่อม ซึ่งเกิดจากการสึกหรอและการเสื่อมของกระดูกอ่อน (cartilage)
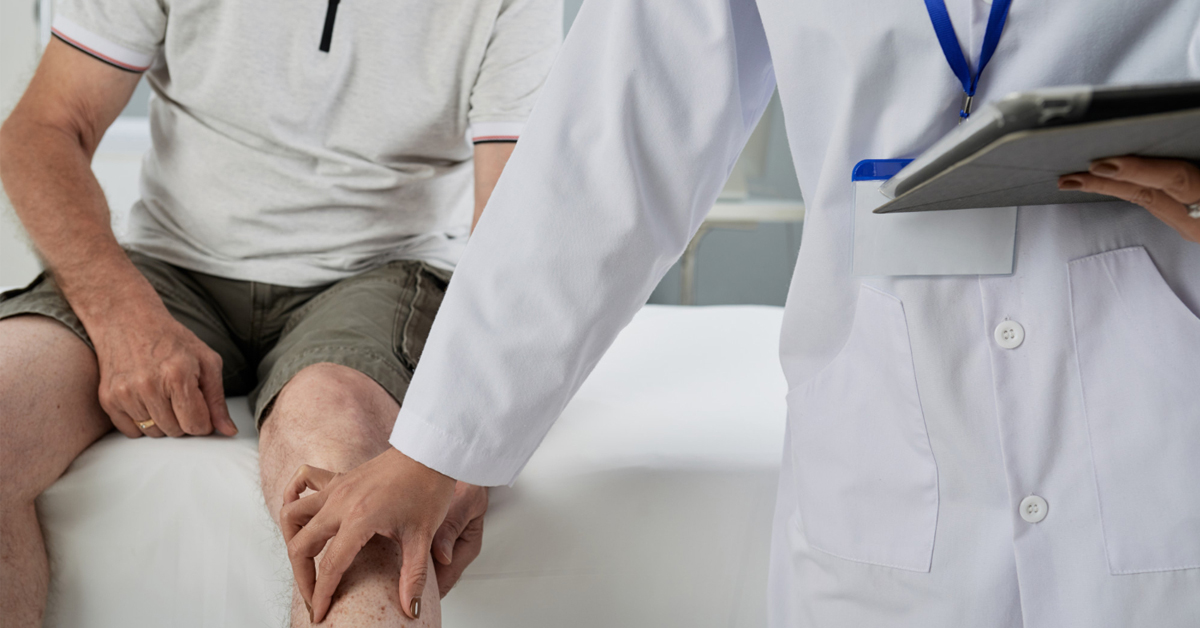
การรักษาข้อเข่าเสื่อมสามารถรักษาได้ด้วยวิธีใดบ้าง ?
ข้อเข่าเสื่อมเป็นภาวะที่เกิดจากการสึกหรอของกระดูกต่อยางหรืออ่อนเนื้อที่ข้อเข่า ซึ่งมีผลส่งผลต่อการเคลื่อนไหวของข้อเข่าและอาจก่อให้เกิดอาการปวด การรักษาข้อเข่าเสื่อมหรือการดูแลโรคข้อเข่าเสื่อมมีหลายวิธี โดยแบ่งเป็นการรักษาแบบไม่ผ่าตัดและการรักษาด้วยวิธีผ่าตัด

การรับมือ “ลูกติดจอ” ปัญหาในยุคดิจิทัลที่ไม่ควรละเลย
เด็กที่ใช้เวลากับโทรศัพท์มือถือหรือทีวีมากเกินไป ทำให้เกิดปัญหาทั้งด้านสุขภาพร่างกาย สุขภาพจิต การเรียนรู้ สังคม และการสื่อสาร วิธีจัดการที่เหมาะสมจึงเป็นสิ่งสำคัญ
แชร์ 9 ข้อดีของการมีบ้านที่หลายคนไม่เคยรู้มาก่อน
การมีบ้านไม่เพียงแต่เป็นการสร้างที่อยู่อาศัย แต่ยังเป็นการสร้างพื้นที่สำหรับการเติบโต ความสุข และความทรงจำของครอบครัว ด้านล่างนี้คือข้อดีหลักๆ ของการมีบ้าน

เพิ่มชีวิตชีวาให้บ้านได้ง่าย ๆ ด้วยการปลูกไม้ดอก
ไม้ดอกหลายสายพันธุ์ได้รับความนิยมทั่วโลก ซึ่งสามารถปลูก และดูแลได้ด้วยขั้นตอนง่าย ๆ ทั้งยังมีประโยชน์ด้านความสวยงาม ดีต่อสุขภาพจิต รวมถึงดีต่อสัตว์ และสิ่งแวดล้อม

คู่มือเลี้ยงนก สำหรับมือใหม่ และ 5 สายพันธุ์นกน่าเลี้ยง
นกเป็นสัตว์เลี้ยงที่มีความฉลาดและขี้เล่น การเริ่มต้นเลี้ยงต้องพิจารณาปัจจัยต่าง ๆ ตั้งแต่ สายพันธุ์ สถานที่ อาหาร ความสะอาด ตลอดจนคอยสังเกตพฤติกรรมอย่างสม่ำเสมอ

ทำความรู้จักกับ พุดเดิ้ล (Poodle) น้องหมาขนปุกปุยสุดน่ารัก!
พุดเดิ้ล (Poodle) สุนัขที่มีต้นกำเนิดจากประเทศเยอรมัน ด้วยขนหนาปุกปุยมาพร้อมดวงตากลมโตเป็นเอกลักษณ์ เรียกว่าใครได้เห็นเป็นต้องหลงรัก มาทำความรู้จักให้มากขึ้นกัน

How to อาบน้ำน้องหมาในช่วงหน้าฝน
หน้าฝนและความชื้น เป็นสภาพแวดล้อมที่ช่วยให้เชื้อราเจริญเติบโตได้ดี สำหรับบ้านที่เลี้ยงสุนัข การอาบน้ำอย่างถูกวิธี จะช่วยหลีกเลี่ยงปัญหาสุขภาพผิวหนังช่วงฤดูฝนได้

สายพันธุ์สุนัขที่ได้รับความนิยม และการเลือกให้เหมาะสมกับไลฟ์สไตล์
การเลี้ยงสุนัขดีต่อสุขภาพกายและจิตใจ แต่ต้องมีความพร้อมในหลาย ๆ ด้าน ซึ่งแต่ละสายพันธุ์จะมีลักษณะ และพฤติกรรมที่ต่างกัน การเลือกให้เหมาะสมกับไลฟ์สไตล์จึงสำคัญที่สุด






ดีจริงไหม? ข้อควรรู้ก่อนรีไฟแนนซ์ (Refinance)
รีไฟแนนซ์ (Refinance) คือการทำสัญญาเงินกู้ใหม่แทนสัญญาเงินกู้เดิม เพื่อลดภาระดอกเบี้ยที่สูงขึ้น แต่ควรพิจารณาค่าใช้จ่าย และระยะเวลาผ่อนที่เพิ่มขึ้นอย่างถี่ถ้วน

เส้นทางของมือใหม่ ก้าวแรกสู่โลกการลงทุน
สำหรับมือใหม่ที่พึ่งเริ่มลงทุน การตั้งเป้าหมายที่ชัดเจน ประเมินความเสี่ยง รวมถึงสร้างแผนการลงทุนที่ดี จะช่วยเพิ่มโอกาสประสบความสำเร็จและบรรลุเป้าหมายในการลงทุนได้
แชร์ 9 ข้อดีของการมีบ้านที่หลายคนไม่เคยรู้มาก่อน
การมีบ้านไม่เพียงแต่เป็นการสร้างที่อยู่อาศัย แต่ยังเป็นการสร้างพื้นที่สำหรับการเติบโต ความสุข และความทรงจำของครอบครัว ด้านล่างนี้คือข้อดีหลักๆ ของการมีบ้าน
ฮวงจุ้ยคอนโด แบบไหนอยู่แล้วสุข การงานมั่นคง การเงินมั่งคั่ง
ฮวงจุ้ยคอนโด ทำเลที่ตั้ง การเลือกชั้น เลขห้อง และสีมงคล ตามธาตุทั้ง 5 ได้แก่ ธาตุดิน ธาตุทอง ธาตุน้ำ ธาตุไม้ ธาตุไฟ ลักษณะห้องที่ต้องเลี่ยง พร้อมวิธีปรับฮวงจุ้ย

5 วิธีถนอม Notebook ยืดอายุการใช้งาน ให้ยาวนานขึ้น
การดูแลโน้ตบุ๊กไม่ใช่แค่การดูแลภายนอกเท่านั้น แต่ยังรวมถึงการจัดการซอฟต์แวร์ ตลอดจนข้อมูลภายในเครื่องด้วย เพื่อให้มีอายุการใช้งานที่ยาวนานและทำงานได้ดีอยู่เสมอ

เทคนิคการใช้ Microsoft PowerPoint แบบมือโปร!
Ms PowerPoint พัฒนาขึ้นเพื่อสร้างและนำเสนอสไลด์ ที่ใช้งานง่าย มือใหม่ก็ทำได้ มาดูการเริ่มต้นใช้งานและคีย์ลัดที่ใช้บ่อย เพื่อให้การทำงานของคุณสะดวกรวดเร็วมากขึ้น